1. 判断方式与方法
垃圾收集器对 Java堆里的对象 是否进行回收的判断准则:
Java对象是存活 or 死亡:判断对象为死亡才会进行回收
在Java虚拟机中,判断对象是否存活有2种方法:
- 引用计数法
- 引用链法(可达性分析法)
1.1. 引用计数法
方法描述
给 Java 对象添加一个引用计数器,每当有一个地方引用它时,计数器 +1;引用失效则 -1;
判断对象存活准则
当计数器不为 0 时,判断该对象存活;否则判断为死亡(计数器 = 0)。
优点
实现简单、判断高效
缺点
无法解决对象间相互循环引用的问题 : 即该算法存在判断逻辑的漏洞
背景
1 | // 对象objA 和 objB 都有字段 name |
问题
实际上这两个对象已经不可能再被访问,应该要被垃圾收集器进行回收
但因为他们相互引用,所以导致计数器不为0,这导致引用计数算法无法通知垃圾收集器回收该两个对象
++正由于该算法存在判断逻辑漏洞,所以Java虚拟机没有采用该算法判断Java是否存活++。
2.2、引用链法(可达性分析法)
很多主流商用语言(如Java、C#)都采用引用链法判断Java对象是否存活。
含3个步骤:
- 可达性分
- 析第一次标记 & 筛选
- 第二次标记 & 筛选
2.2.1 可达性分析
方法描述
将一系列的 GC Roots 对象作为起点,从这些起点开始向下搜索。
可作为 GC Root 的对象有:
- Java虚拟机栈(栈帧的本地变量表)中引用的对象
- 本地方法栈 中 JNI引用对象
- 方法区 中常量、类静态属性引用的对象
Java 进行GC的时候会从GC root进行可达性判断,常见的GC Root有如下:
- Class - 由系统类加载器(system class loader)加载的对象,这些类是不能够被回收的,他们可以以静态字段的方式保存持有其它对象。我们需要注意的一点就是,通过用户自定义的类加载器加载的类,除非相应的java.lang.Class实例以其它的某种(或多种)方式成为roots,否则它们并不是roots,.
- Thread - 活着的线程
- Stack Local - Java方法的local变量或参数
- JNI Local - JNI方法的local变量或参数
- JNI Global - 全局JNI引用
- Monitor Used - 用于同步的监控对象
- Held by JVM - 用于JVM特殊目的由GC保留的对象,但实际上这个与JVM的实现是有关的。可能已知的一些类型是:系统类加载器、一些JVM知道的重要的异常类、一些用于处理异常的预分配对象以及一些自定义的类加载器等。然而,JVM并没有为这些对象提供其它的信息,因此需要去确定哪些是属于”JVM持有”的了。
向下搜索的路径 = 引用链
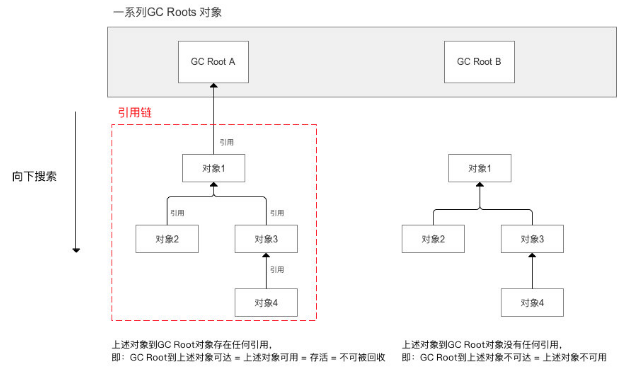
判断对象是否可达标准
当一个对象到 GC Roots没有任何引用链相连时,则判断该对象不可达,比如上图右边的形式。
没有任何引用链相连 = GC Root到对象不可达 = 对象不可用
注意:Java9中已经明确弃用了finalize方法
为什么呢?简单说,你无法保证finalize什么时候执行,执行的是否符合预期。使用不当会影响 性能,导致程序死锁、挂起等。千万不要指望 finalize 去承担资源释放的主要职责,多让finalize作为后的“守门员”(也就是如下的行为两次标记筛选)
++可达性分析 仅仅只是判断对象是否可达,但还不足以判断对象是否存活 / 死亡,++
当在 可达性分析 中判断不可达的对象,只是“被判刑” = 还没真正死亡
不可达对象会被放在”即将回收“的集合里。
要判断一个对象真正死亡,还需要经历两个阶段:
第一次标记 & 筛选 finalize方法存在
第二次标记 & 筛选
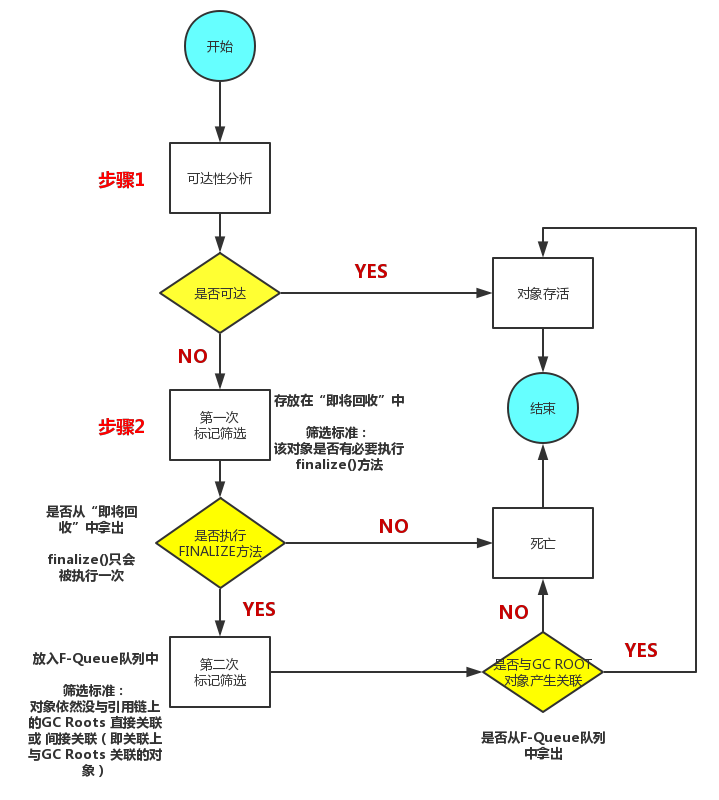
2.2.2 第一次标记 & 筛选
对象在可达性分析中被判断为不可达后,会被第一次标记 & 准备被筛选
方法描述
- 不筛选:继续留在 ”即将回收“的集合里,等待回收;
- 筛选:从 ”即将回收“的集合取出
筛选标准
- 该对象是否有必要执行 finalize()方法
- 若有必要执行(人为设置),则筛选出来,进入下一阶段(第二次标记 & 筛选);
- 若没必要执行,判断该对象死亡,不筛选 并等待回收
- 当对象无 finalize()方法 或 finalize()已被虚拟机调用过,则视为“没必要执行”
2.2.3 第二次标记 & 筛选
当对象经过了第一次的标记 & 筛选,会被进行第二次标记 & 准备被进行 筛选
方法描述
该对象会被放到一个 F-Queue 队列中,并由 虚拟机自动建立、优先级低的Finalizer 线程去执行 队列中该对象的finalize(),finalize()只会被执行一次,但并不承诺等待finalize()运行结束。这是为了防止 finalize()执行缓慢 / 停止 使得 F-Queue队列其他对象永久等待。
筛选标准
在执行finalize()过程中,若对象依然没与引用链上的GC Roots直接关联或间接关联(即关联上与GC Roots 关联的对象),那么该对象将被判断死亡,不筛选(留在”即将回收“集合里)并等待回收
3、引用相关
不管是引用计数还是可达性分析,都和引用有关。 Java中引用包括:
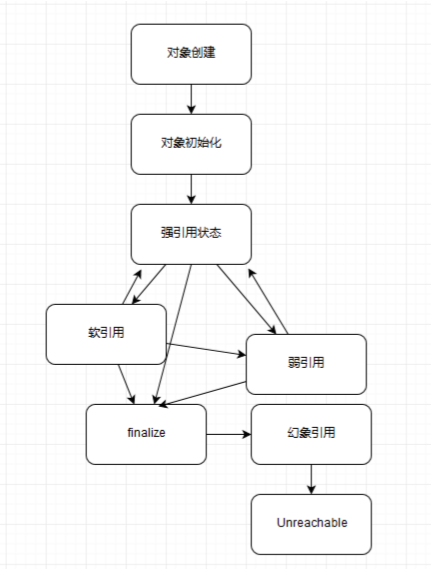
1、强引用
最普遍的引用,只要强引用存在,对象肯定不会被回收。
++obj就是强引用。通过关键字new 创建的对象所关联的引用就是强引用++。 当JVM内存空间不足,JVM宁愿抛出OutOfMemory Error运行时错误(OOM),使程序异常终止,也不会靠随意回收具有强引用的“存活”对 象来解决内存不足的问题。对于一个普通的对象,如果没有其他的引用关系,只要超过了引 用的作用域或者显式地将相应(强)引用赋值为 null,就是可以被垃圾收集的了,具体回收 时机还是要看垃圾收集策略。
2、软引用
描述有用但并非必需的对象,当内存不足时,就会回收这些对象。Java中提供SoftReference类。 一般用于内存敏感的高速缓存中。
图片缓存框架中,“内存缓存”中的图片是以这种引用来保存,使得JVM在发生 OOM之前,可以回收这部分缓存
3、弱引用
描述非必需对象,强度比软引用更弱。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。Java中提供WeakReference类。
在静态内部类中,经常会使用虚引用。例如,一个类发送网络请求,承担callbac k的静态内部类,则常以虚引用的方式来保存外部类(宿主类)的引用,当外部类需要被JVM回 收时,不会因为网络请求没有及时回来,导致外部类不能被回收,引起内存泄漏
4、虚引用
又称幽灵引用或幻影引用,最弱的一种引用关系。虚引用对对象的生命周期不会有任何影响,不能通过虚引用取得对象的实例。唯一的目的是,设置虚引用的对象在被回收时会收到
应用场景:可用来跟踪对象被垃圾回收器回收的活动,当一个虚引用关联的对象被垃圾收集 器回收之前会收到一条系统通知。
这种引用的get()方法返回总是null,所以,可以想象,在平常的项目开发肯定 用的少。但是根据这种引用的特点,我想可以通过监控这类引用,来进行一些垃圾清理的动作。可以参考jdk内部cleaner使用